Common Lisp for Data Scientists: A Field Report From My “Tidyverse Weekend” (Powered by Antigravity)

Rebuilding Tidyverse with Common Lisp
There’s a very specific kind of feeling you get when you open a dataset and your brain immediately wants to do the same ten moves it always does:
- peek at the columns
- clean up a few names
- filter down to the interesting subset
- reshape wide ↔ long
- join in some reference table
- summarize
- export something a colleague can open without installing a toolchain from 2009
If you’re a data person, that muscle memory usually spells R + Tidyverse (or Python + pandas, depending on how much pain you enjoy per line of code).
And yet… I keep wanting to do this work in Common Lisp.
Not because I’m nostalgic. Not because I enjoy suffering.
But because Lisp has a superpower that data tooling rarely gets to exploit properly:
The language itself is the extension mechanism.
Macros. DSLs. Real composability. No fake metaprogramming. No ritualistic “eval(parse(text=…))” energy. Just the actual thing.
So I ran an experiment:
What if we rebuild “enough Tidyverse” in Common Lisp to be useful for daily data work — and we do it fast, openly, and iteratively?
I used antigravity for vibecoding, and this article is a field report: what I built, how it fits together, how to try it, and how you can jump in without having to decode my brain first.
The premise: we don’t need 100% Tidyverse — we need “daily useful”
Tidyverse is huge. And it’s not just APIs; it’s culture. It’s a workflow that feels like a fluent conversation with your data.
But here’s the truth most re-implementations miss:
You don’t need full coverage.
You need:
- the 20% of verbs you use 80% of the time
- a consistent data model
- pipelines that don’t feel like punishment
- IO that handles real-world files
- extensibility so the community can grow it naturally
So my goal is not “Tidyverse, but in Common Lisp, perfect and complete.”
My goal is: Common Lisp that a data scientist can actually use.
If a function is rarely used, we skip it.
If nobody misses it, it stays omitted.
If somebody misses it, we add it.
That’s the whole strategy.
What I built in a few days
Here’s the current set of packages (all under my GitHub account):
- cl-excel — read/write Excel tables
- cl-vctrs-lite — a small core inspired by vctrs
- cl-tibble — “tibbles” (pleasant data frames)
- cl-dplyr — data manipulation verbs
- cl-tidyr — reshaping / preprocessing
- cl-readr — CSV/TSV read/write
- cl-forcats — categorical helpers
- cl-lubridate — date/time convenience
- cl-stringr — smoother string work
And each repo includes SPEC.md (what the package tries to be) and AGENTS.md (how to vibecode/contribute in a structured way).
So if you want to improve something, you don’t have to reverse-engineer intent from a pile of commits. You get the “why” and the “how” up front.
The vibe: a “data stack” that feels like Lisp, not a ported museum exhibit
A port can easily become uncanny: it looks like Tidyverse, but it behaves like a translation.
I’m aiming for something else:
- Keep the mental model (verbs, pipelines, tidy data ergonomics)
- Use Lisp strengths (macros, extensible generic functions, real DSLs)
- Stay practical (IO, table printing, simple entry points)
Also: I’m not translating rlang.
In R, rlang exists because R needs a lot of scaffolding to simulate what Lisp can do natively.
In Common Lisp, we already have the big guns. If we need non-standard evaluation patterns, we can build them directly and cleanly.
A quick tour: what “daily data work” looks like
Let’s do the most boring, realistic thing imaginable:
- read a CSV
- clean a column or two
- filter
- group & summarize
- export to Excel
That boring workflow is exactly what decides whether a toolchain lives or dies.
The workflow (conceptually)
- cl-readr gets data in and out of delimited files
- cl-tibble gives you a pleasant tabular object
- cl-dplyr manipulates it with verbs
- cl-stringr / cl-lubridata / cl-forcats provide the “small sharp tools”
- cl-excel writes the result into something your collaborator will actually open
A “shape” of code you can expect
I’m keeping this hands-on, so here’s a representative sketch of the style I’m building toward. The exact function names may evolve as the repos settle, but the idea is stable:
;; Pseudo-realistic example of the intended workflow style
(defparameter *df*
(readr:read-csv "sales.csv"))
(defparameter *clean*
(-> *df*
(dplyr:mutate :region (stringr:str-to-upper :region))
(dplyr:filter (>= :revenue 1000))
(dplyr:group-by :region)
(dplyr:summarise :n (dplyr:n)
:total (dplyr:sum :revenue))
(dplyr:arrange (dplyr:desc :total))))That -> pipeline style (and placeholder-like ergonomics) is intentional: you should be able to read it top-to-bottom like a recipe, not like a nested-parentheses archaeological dig.
Then exporting:
(excel:write-table "report.xlsx" *clean* :sheet "Summary")This is the “data scientist reality test.”
If this feels smooth, people will use it. If it feels like homework, they won’t.
Why antigravity made this feasible
Let’s be honest: building a family of coherent libraries is usually a slow grind because you’re constantly context-switching:
- design decisions
- naming
- docs
- tests
- edge cases
- “what should the idiomatic API be?”
- “how do I keep it consistent across packages?”
This is where vibecoding (with antigravity) shines if you constrain it correctly.
My rule was simple:
- Write SPEC.md first (what the package is, what it is not)
- Write AGENTS.md (how contributions should happen, conventions, tests, style)
- Generate code iteratively in small steps
- Keep APIs boring and composable
- Prefer “add” over “replace” (backwards compatibility is a feature)
The result is not “AI wrote a library.”
The result is: I could move at the speed of design, not the speed of boilerplate.
And that is the only reason this many repos exist after a couple of days.
The hidden engineering decision: a small core first (vctrs-lite → tibble → verbs)
If you’ve ever looked at Tidyverse internals, you know the magic isn’t only in dplyr.
A lot of stability comes from foundational ideas:
- vectors that behave consistently
- predictable recycling rules
- well-defined missingness
- robust type conversions
- a data frame structure that prints nicely and doesn’t surprise you
That’s why cl-vctrs-lite exists.
Then cl-tibble builds on that, and the rest can treat “a table” as a stable thing.
This is the difference between:
- “a bunch of functions that kind of work”and
- “a stack that can grow without collapsing under its own edge cases”
How you can try it quickly
Everything is on GitHub under this account:
https://github.com/gwangjinkim/
And the repos include installation notes (Quicklisp/local projects, ASDF load paths, etc.). The intent is: clone → load system → run examples → file an issue when something feels off.
If you’re a Common Lisp person, you already know the fastest way to help isn’t heroic refactors.
It’s:
- run it on your machine
- try a realistic dataset
- hit a rough edge
- open an issue with a tiny reproduction
- optionally add a test + PR
Which is why I’m also adding an Issues template, because “comment bait” is not just marketing — it’s how you surface real use cases early.
What I want from the community (and what I don’t)
I want:
- people to try it on real data
- complaints about missing verbs you genuinely miss
- suggestions for a more lispy DSL (as additions, not replacements)
- small PRs that improve consistency, tests, docs, or edge cases
- package authors to tell me where I’m reinventing something that already exists
I don’t want:
- perfection paralysis
- ideology wars about parentheses
- “this should be rewritten completely” drive-by comments
- a purity contest that makes the project unshippable
The point is to get a usable toolkit into people’s hands, then evolve it in public.
The pitch (without hype): why this could actually matter
Common Lisp already has the ingredients:
- a serious, highly optimized compiler (SBCL)
- interactive development
- macros that can create truly ergonomic data DSLs
- generic functions that make extensibility feel natural
- a community that understands “build small, compose, iterate”
What it’s missing is a default daily-driver story for data work.
A “Tidyverse-ish” stack for Common Lisp doesn’t have to be perfect.
It just has to be good enough that a data scientist can say:
“Yes. I can do my normal workflow here. And it feels… surprisingly nice.”
That’s the bar.
And honestly, it’s a very reachable bar.
If you want to join: pick one sharp improvement
If you’re curious and want to contribute, here are high-leverage targets:
- one real dataset test (CSV → transform → export)
- printing / formatting improvements (tibbles live or die by ergonomics)
- edge cases around missing values
- joins (always joins)
- a small set of “most-missed” helpers you personally use weekly
Or just file issues. Seriously. Issues are how this becomes real.
Repos
Here’s the hub again:
If you want a starting point, the simplest on-ramp is usually:
- cl-readr + cl-tibble + cl-dplyrand then cl-excel for the “export to humans” step.
Appendix: How to try it in 5 minutes (Roswell-only, fastest path)
The fastest way from zero to hero (running SBCL with all the packages installed) is via Roswell, a Common Lisp version and package manager.
1) Install Roswell
# macos
brew install roswell
# linux (ubuntu/debian) - Windows users - use WSL2 (ubuntu)
sudo apt-get update
sudo apt-get install -y roswell
verify:
ros --version2) Install the newest SBCL (via Roswell)
Roswell can install SBCL - the newest version - in two common ways:
# fast binary (recommended):
ros install sbcl-bin
# pure from source:
ros install sbclSelect the sbcl then:
ros use sbcl-bin
# or: ros use sbclRoswell will also bootstrap Quicklisp automatically the first time it needs it.
3) Install the packages
Installing GitHub repository packages from Roswell is super easy:
ros install gwangjinkim/cl-readr
ros install gwangjinkim/cl-tibble
ros install gwangjinkim/cl-dplyr
ros install gwangjinkim/cl-excel
ros install gwangjinkim/cl-forcats
ros install gwangjinkim/cl-stringr
ros install gwangjinkim/cl-tidyr
ros install gwangjinkim/cl-lubridate
Create a tiny CSV in your shell:
cat > /tmp/mini.csv <<'CSV'
region,revenue
eu,1200
eu,50
eu,1000
us,2000
us,700
us,1000
CSV4) Start a SBCL session in Roswell
For convenience install rlwrap :
# macos
brew install rlwrap
# linux
sudo apt install rlwrapAnd start your SBCL session via Roswell by:
rlwrap ros run
ros run starts SBCL inside Roswell. But SBCL doesn't have some niceties (that you can move around using arrows and get previous commands). Rlwrap wraps this terminal and provides the nicer interface.
The much better experience would be to have a SBCL session running in an IDE like Emacs. I described the setup here:
Try it in 2 minutes: from CSV to Excel, with a tiny “tidy” pipeline
Here’s the quickest way to see what the stack feels like. We’ll:
- read a CSV
- upper-case the region column
- keep only rows with revenue >= 1000
- group by region
- compute n (row count) and total (sum of revenue)
- sort by total descending
- write the result to an .xlsx
1) Load the packages
(ql:quickload '(:cl-dplyr :cl-readr :cl-stringr :cl-tibble))
2) Run the pipeline
(defparameter *df*
(readr:read-csv "/tmp/mini.csv"))
(defparameter *clean*
(dplyr:-> *df*
(dplyr:mutate :region (stringr:str-to-upper :region))
(dplyr:filter (>= :revenue 1000))
(dplyr:group-by :region)
(dplyr:summarise :n (dplyr:n)
:total (dplyr:sum :revenue))
;; sorting helper may evolve; if desc isn't available yet,
;; arrange also accepts a spec like '(:total :desc)
(dplyr:arrange '(:total :desc))))3) Export to Excel
(excel:write-xlsx *clean* #p"~/Downloads/report.xlsx" :sheet "Summary")At this point you should have a report.xlsx you can open immediately. It contains exactly what the pipeline says: rows filtered by revenue >= 1000, aggregated by region, with total being the sum and n counting how many rows contributed — then ordered by total descending.
(Yes, I'm including a screenshot because nothing builds trust like an actual file that opens.)
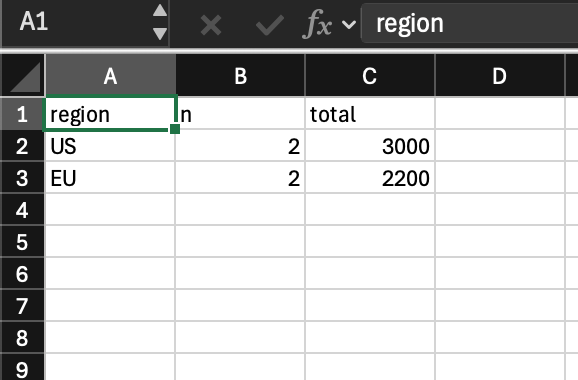
“Can I make it look even more like Tidyverse?”
You can, but with the usual Lisp tradeoff: convenience vs. namespace hygiene.
If you really want the ultra-compact style, you can import symbols into your current package:
(ql:quickload '(:cl-dplyr :cl-readr :cl-stringr :cl-tibble :cl-excel))
(use-package '(:cl-dplyr :cl-stringr :cl-excel))Then the same pipeline can look like this:
(defparameter *df* (readr:read-csv "/tmp/mini.csv"))
(defparameter *clean*
(-> *df*
(mutate :region (str-to-upper :region))
(filter (>= :revenue 1000))
(group-by :region)
(summarise :n (n)
:total (sum :revenue))
(arrange '(:total :desc))))
(write-xlsx *clean* #p"~/Downloads/report1.xlsx" :sheet "Summary")That’s the “I’m doing data work like with R”.
But: importing lots of common names can collide with other packages (or even implementation-provided symbols). You’ve already seen real examples like cl-readr:read-file vs. cl-excel:read-file, or cl-dplyr:rename colliding with implementation symbols (sb-ext:rename).
The direction from here: one integration package, clean namespaces, no package name conflicts
The next step is an integration system: cl-tidyverse.
The job of cl-tidyverse won’t be “yet another layer.” It will be the boring, valuable thing:
- load the whole stack in one shot
- provide a curated user-facing package that resolves name conflicts intentionally
- keep the underlying libraries honest (small, composable, and safe to load together)
Inside cl-dplyr, I’m already steering toward a conflict-proof approach by keeping the truly safe public API in dotted verb forms (.mutate, .filter, .group-by, etc.) and dotted helpers (.sum, .min, .max, …). The pipeline macro can then rewrite “pretty” verbs into the dotted ones internally. That lets you write clean code while keeping the exported surface conservative.
That’s the overall philosophy here: make the common path delightful, and make the system robust enough to grow.
If you’re curious, try the snippet above on a real CSV you care about. If something feels off, file an issue with the smallest reproduction you can manage. That feedback is the entire point of doing this in public.
Common Lisp doesn’t need a miracle to be useful for data work. It needs a stack that’s practical, iterable, and slightly shameless about optimizing for daily ergonomics.
That’s what I’m trying to build in this project.